05:00
Week 2 Starter File

Basic Manipulations
The following sections of the book (R for Data Science) used for the first portion of the course are included in the first week:
- Data Transformation: Sections: from 3 to 3.3 & part of 3.5 included
Link to other resources
Internal help: posit support
External help: stackoverflow
Additional materials: posit resources
Cheat Sheets: posit cheat sheets
While I use the book as a reference the materials provided to you are custom made and include more activities and resources.
If you understand the materials covered in this document there is no need to refer to other resources.
If you have any troubles with the materials don’t hesitate to contact me or check the above resources.
Our Data Science Model
Load packages
This is a critical task:
Every time you open a new R session you will need to load the packages.
Failing to do so will incur in the most common errors among beginners (e.g., ” could not find function ‘x’ ” or “object ‘y’ not found”).
So please always remember to load your packages by running the
libraryfunction for each package you will use in that specific session 🤝
Get to know your data
Getting to know your data is the starting point of our journey. The below functions have different purposes but they will help you to understand your dataset.
Important
Initiating your data analytics project with a thorough exploration of your dataset is crucial. A deep understanding of your data lays the foundation for formulating pertinent questions and executing appropriate analytical steps. Without this intimate knowledge, you risk misguiding your analysis or overlooking critical insights
Data types
Only the most used ones are covered below:
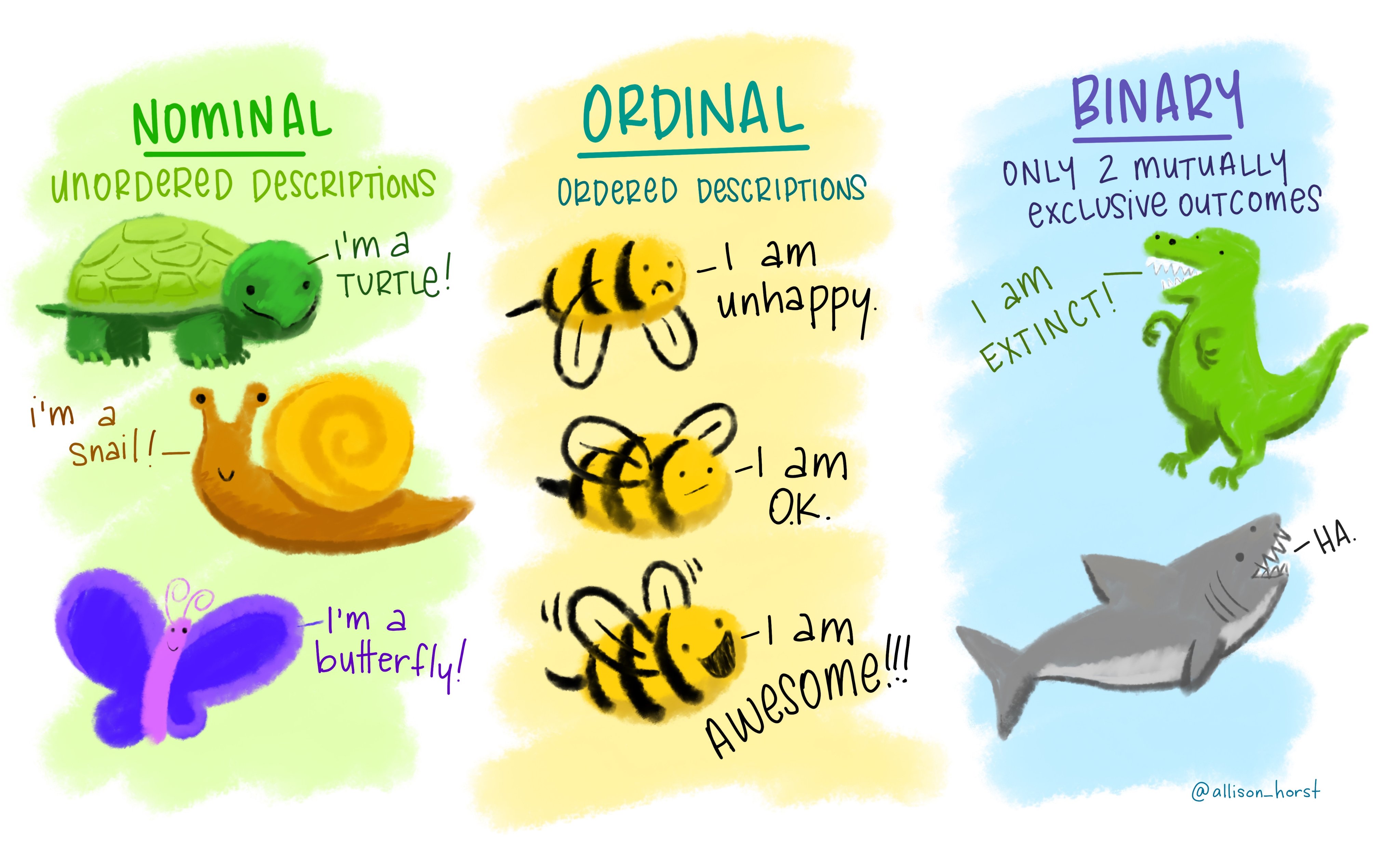
intstands for integers (1,2,3).dblstands for doubles, or real numbers (-1, 1.5,4/5).

datestands for dates (01/21/2025).dttmstands for date-times, a date + a time (01/21/2025 11:00 am).fctrstands for factors, which R uses to represent categorical variables with fixed possible values (freshman, sophomore, junior, senior).lglstands for logical, vectors that contain onlyTRUEorFALSEvalues.chrstands for character vectors, or strings (“this is a string”).
Data structures
Only the most used ones are covered below:
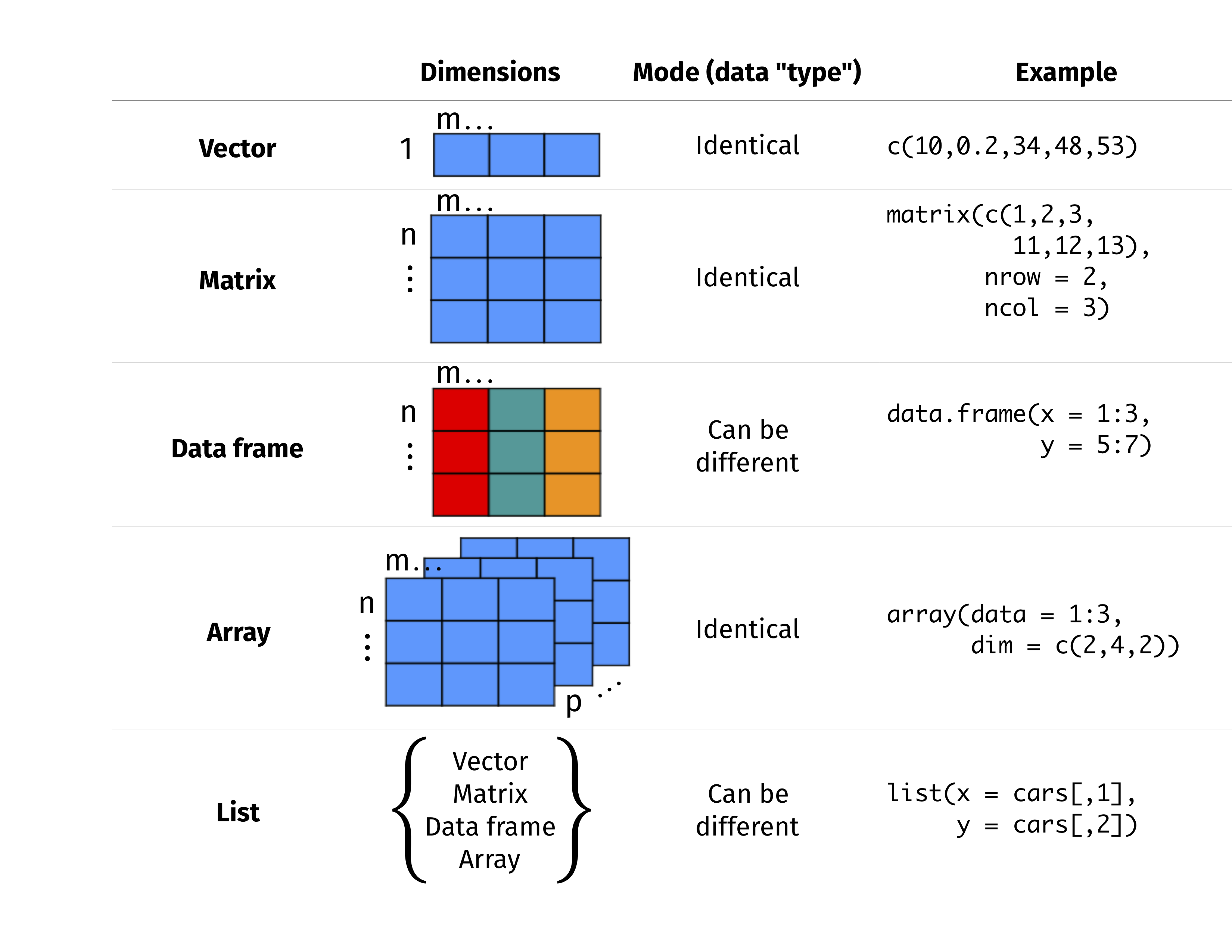
Vector: An atomic vector (or simply vector) is the simplest data structure in R which consists of an ordered set of values of the same type (e.g. numeric, character, date, etc…). A vector of lenght 1 is called ascalar.
Examples:
Remember to always check the objects you create:
Data frame/tibble/dataset: A data frame is a data structure that organizes data into a 2-dimensional table of rows and columns, much like a spreadsheet. Data frames are called tibbles in R (tidyverse).
We can create a tibble by combining two or more vectors of the same length.
Example:
Each vector includes 5 elements (it has a length of 5) and this is why the cob data frame has 5 rows/observations. Moreover we used three vectors in our cob data frame and this is why we have 3 columns/variables. As you can see the vector name has become the column name. Moreover, a tibble structure is not much different than an Excel spreadsheet.
Note
There are other data structures available in R (e.g., matrix, array and list) but we will not use or cover them in this course.
Now that you have a basic understanding of data types and structures (we will cover more about tibble next week) we can dive into useful functions for wrangling your data.
The Tidyverse Universe

5 + 1 Key data manipulation (dplyr package) functions:
Reorder/sort observations/rows (
arrange()).Keep observations/rows based on conditions (
filter()).Pick variables/columns (
select()).Create new variables/columns or update existing ones (
mutate()).Produce descriptive statistics (
summarize()).Change the unit of analysis by creating groups based on one of more variables/columns (
group_by()our +1 function).

How they work?
These six functions provide the verbs for a language of data manipulation. All verbs work similarly, and this is a great news, and have a similar structure:
The first argument is a data frame on which you want to perform a manipulation.
The subsequent arguments describe what do you want to do with the original data frame, using the variable names (without quotes).
The result is a new data frame (remember to assign it to a new object if you want to save the changes).

Data Manipulations - Rows
Arrange()
arrange() changes the order in which rows are presented in the dataset. For example, using an imaginary US tax payers dataset, you will use arrange if you want to sort the dataset by the tax payers last name in decreasing order (Z-A). –> arrange(tax_payers, desc(last_name)) Arrange takes a data frame and a set of column names (or more complicated expressions) to order by. If you provide more than one column name, each additional column will be used to break ties in the values of preceding columns:
Examples:
Example 1: arrange the dataset based on destination increasing alphabetical order
Example 2: arrange the dataset based on distance decreasing order
Activity 1: Arrange (a & d in class; b & c are for practice) - 5 minutes
[Write code just below each instruction; finally use MS Teams R - Forum channel for help on the in class activities/homework or if you have other questions]
Sort flights by distance from smaller to bigger
Reorder flights by air_time from bigger to smaller
Sort flights by arr_delay from smaller to bigger
Reorder flights by month from bigger to smaller
Filter()
filter() is used to include in your dataset only observations that meet one or more logical conditions. For example, you will use filter if from an imaginary US tax payers dataset (tax_payers), you want to continue your analysis only on tax payers that live in Illinois given a states variable (notice that by doing so # of observations/rows decreases while # of variables/columns stays the same). –> filter(tax_payers, state== "IL")
To use filtering effectively, you have to know how to select the observations that you want using the comparison operators. R provides the standard suite: >, >=, <, <=, != (not equal), and == (equal).
Examples:
Example1: flights that traveled more than an hour (use: air_time)
Example 2: flights that traveled to Ohare (ORD)
When you’re starting out with R, the easiest mistake to make is to use = instead of == when testing for equality. When this happens you’ll get an informative error:
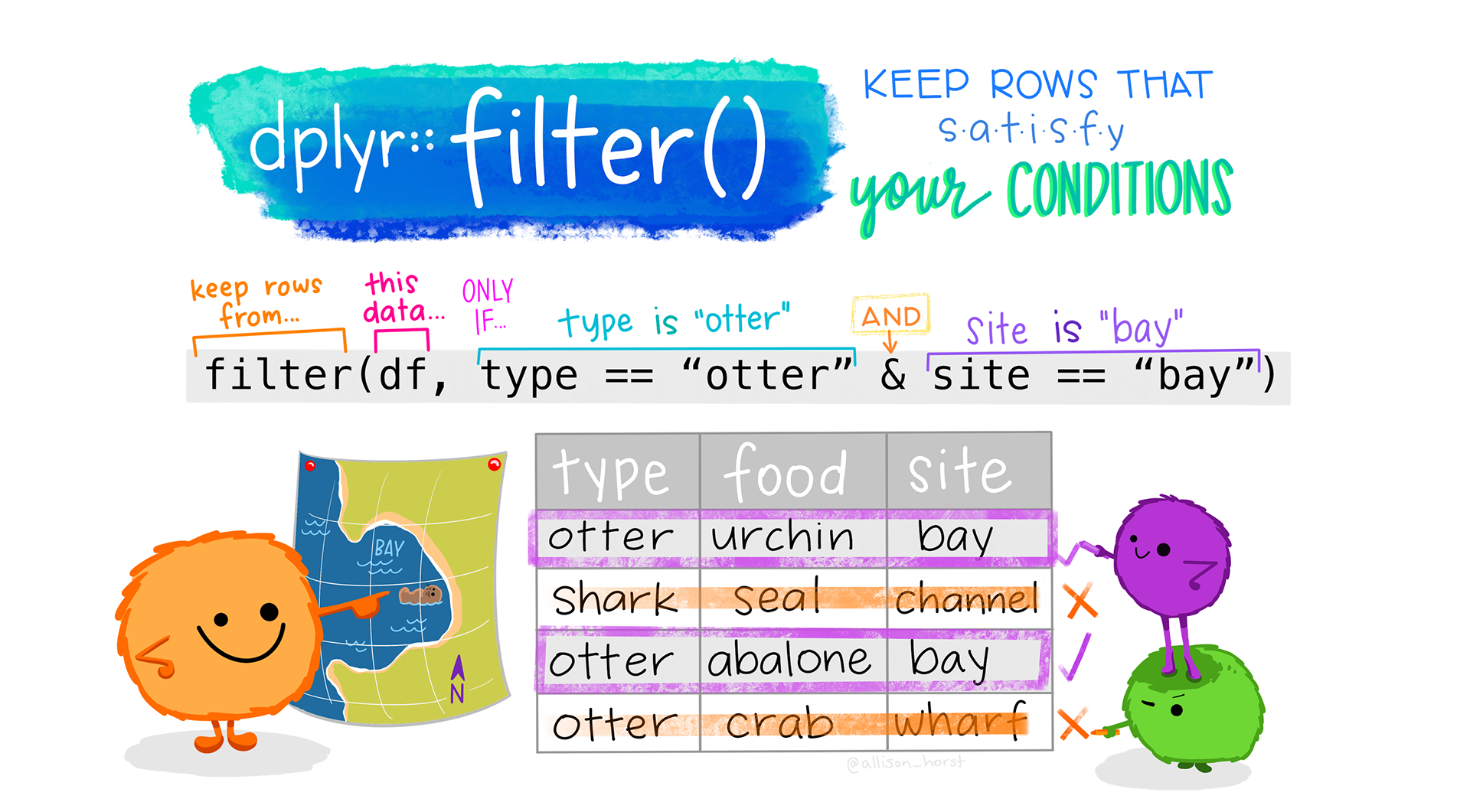
Multiple arguments to filter() are combined with “and”: every expression must be true in order for a row to be included in the output. For other types of combinations, you’ll need to use Boolean operators yourself: & is “and”, | is “or”, and ! is “not”. The , can also be used instead of &. However, I do recommend to use & especially at the beginning as it is easier for you to remind that both conditions must be met for an observation to be included in the analysis. However, if you combine an & and | in the same filter you need parenthesis to separate the & and the | (see below note).
Examples
Example 3: find flights in November and December
Look at the results. Does it make sense to have such filter?
Example 4: find flights in November or December
Now this makes sense as you want to constraint the focus of your analysis to the last two months of the year. You might have an intuition that during the holiday season there is need for more flights/personnel. Check out the syntax month %in% c(11, 12) to avoid writing month == twice.
Example 5: find flights that weren’t delayed (on arrival and departure) by more than two hours
Hours are presented in minutes in the dataset that’s why 120. Again, you need to get to know your data before starting manipulations. If you don’t remember column names check the colnames function (?colnames).
Activity 2: Filter (a & d in class; b & c are for practice) - 5 minutes
[Write code just below each instruction; finally use MS Teams R - Forum channel for help on the in class activities/homework or if you have other questions]
Keep only the flights operated by the “American Airlines” carrier
Keep only the flights with dep_delay or arr_delay bigger or equal than 15 minutes
Keep only the flights with distance smaller or equal than 1010 miles
Keep only the flights that departed in the month of January and that had more than 860 dep_time or arr_time
NOTE
Flights in August and with more than 60 minutes delay (both departure and arrival):
In this case & and , are perfect substitutes. But when there is a | (or) statement –>
Flights in August and with more than 60 minutes delay (departure or arrival):
However be careful because this is line is different from the two line below because the | is affecting the equivalency with the ,. So, if in your filter you have both a & and |, the & and the , are not equivalent. Without the parenthesis between the & and | you will get different and wrong results.
Once you put the parenthesis:
You get the same results.
Data Manipulations - Columns
Select()
select() allows you to continue the analysis only on some specific columns of your original dataset. By using select you can easily subset only variables that you think are useful in completing your analysis. For example, using the same imaginary US tax payer dataset, you want to focus your analysis on just salary, gender and age. It is unnecessary to keep all the other columns as you already know that they are not going to be included in the scope of the analysis –> select(tax_payers, salary, gender, age)
As you can see there are multiple ways to select the same columns (first 3 chunks of code give the same outcome: a dataset with just year, month, day subset), but not all of them have the same efficiency. Imagine selecting the first 15 column using the first chunk of code (you will have to manually type 15 column’s names) compared to using the second line (first column : fifteenth column) or the third (1:15). However, when you use the last two methods I recommend to check the column order using the function colnames().
Examples
Example 1: select the 2nd, 4th and 10th columns
Example 2: select all the columns but the last 3
Moreover, there are a number of helper functions you can use within select():
starts_with("abc"): matches names that begin with “abc”.
ends_with("xyz"): matches names that end with “xyz”.
contains("ijk"): matches names that contain “ijk”.
See ?select for more details.
Activity 3: Select (a & d in class; b & c are for practice) - 5 minutes
[Write code just below each instruction; finally use MS Teams R - Forum channel for help on the in class activities/homework or if you have other questions]
Select the first 10 adjacent columns
Select the columns that contain the word “time”
Select all columns but those that contain the word “time”
Select the columns that start with the letter “d”
Mutate()
mutate() enables you to change the columns available in your original dataset. By using mutate() you can add new columns that are functions of existing columns. For example, in the tax_payers dataset, you note that the salary column is reported in euros rather than dollars. In this case, you want to create a new column that reports salary in euros. To do so you need to multiple the value that are in the original salary by the conversion rate between euros and dollars. –> mutate(tax_payers, salary_USD = salary * 1.1). Note how I chose a meaningful name for the new column, and that the conversion rate at the time I created this teaching file was 1.1.

Moreover, keep in mind that mutate() always adds new columns at the end of your dataset. So, to view the new column you can use select(tax_payers, salary_USD). Nonetheless, If you want to just use the new compute column you can also use the transmute() function (see example below).
Examples
Example 1: using the flights_sml dataset compute a column named gain equal to the difference between departure delay and arrival delay
Example 2: using the flights_sml dataset compute a column named gain equal to the difference between departure delay and arrival delay; a column named hours equal to air time dived by 60; and a column named gain_per_hour equal to gain divided by hours
You can refer to column your are just creating, be careful to the order. Can you invert the order of gain_per_hour and gain? Make sure you try it!
Example 3: using the flights_sml dataset compute a column named speed equal to the variable distance divided by air time multiplied by 60 (we want speed in mph). Use transmute instead of mutate. What is the difference?
If you only want to keep the new variables, use transmute()!
Activity 4: Mutate (a & d in class; b & c are for practice) - 5 minutes
[Write code just below each instruction; finally use MS Teams R - Forum channel for help on the in class activities/homework or if you have other questions]
Compute a variable that shows the difference between scheduled departure time and the actual time of departure
Compute a variable that shows the distance divided by the air_time
Compute a variable that shows the difference between scheduled arrival time and the actual time of arrival
Compute a variable that shows the sum of the departure delay and the air time (make sure to show only the new column)
Data Manipulations - Aggregation
Summarize()
summarize() enables you to compute descriptive statistics of your dataset. summarize() collapses a data frame to a single row. For example, if you want to compute the average salary of the observation of the tax payers in your dataset, summarize will return to you one row that contains the average value. –> summarize(tax_payers, avg_salary = mean(salary)). Note how I chose a meaningful name for the output of my summary.
We will talk later about NAs (missing values) but the na.rm=TRUE argument is critical if the column you are using for your average contains missing values. Let’s remove that argument and see what happens.
Examples
Example 1: compute the mean of the arrival delay column
Example 2: find the max distance
summarize() is not terribly useful unless we pair it with group_by() or better it is pretty limited to summarize a single value per column.
For example, imagine that you want to see how the average salary of tax payers change depending on their age. In this case, you need to first group_by your dataset using the age column and then compute the average salary. Thanks to the combination of group_by and summarize you will able to explore if the average salary of a 40 years old tax payer is on average higher/lower or equal to the ones of a 21 years old tax payer.
Summarize + group_by()
So, when you use the group_by() function you can change the unit of analysis from the complete dataset to individual groups (columns that caught your attention). group_by will create a group for each unique value available in the selected column.
Then, when you use the dplyr functions on a grouped data frame they’ll be automatically applied “by group”.
Examples
Example 1: Compute the average departure delay for each day of the month
The above analysis could help indicate if there are some days in which delays are more common.
Example 2: Compute the average arrival delay for each airline
The above results help in checking the arrival delay performance of different airlines.
Example 3: Compute the median departure delay for each day of the year
With these results we can see what days were the most problematic in the 2023. We could leverage arrange to sort for the biggest delay to the smallest one. Can you do that given the above code?
The above results are interesting. However, having a full descriptive table can be more useful than just averages. In fact, averages can be skewed by outliers. Can we create a full descriptive statistics table of the carrier example?
Together group_by() and summarize() provide one of the tools that you’ll use most commonly when working with dplyr: grouped summaries. These two functions are extremely useful to create descriptive statistics of the column of your dataset.
Activity 5: Summarize (a & d in class; b & c are for practice) - 5 minutes
[Write code just below each instruction; finally use MS Teams R - Forum channel for help on the in class activities/homework or if you have other questions]
Compute the max dep_delay
Compute the min air_time
Compute mean and standard deviation of the distance per each destination
Compute the max and min of air_time per each month
Note
We will cover the remaining sections of chapter 3 in the next class make sure that your are not behind and you understand what we covered so far.
Important
Please remember that if you want to save the changes made through the 5+1 manipulations functions you should use the <- and assign those changes to an object!
